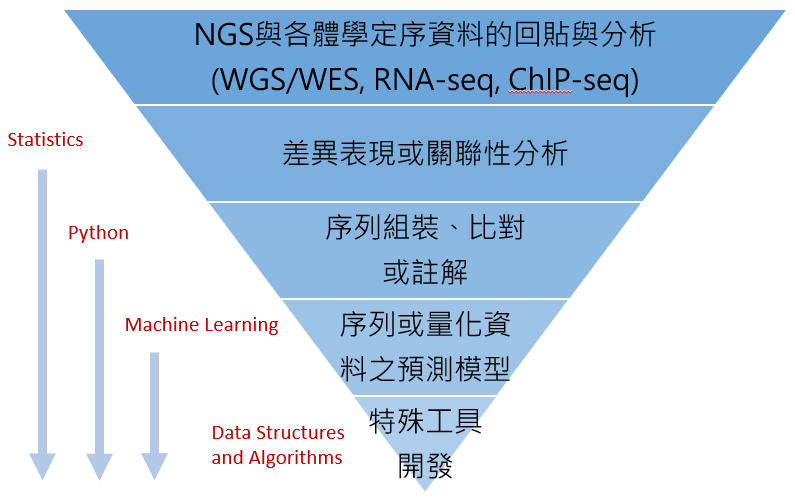
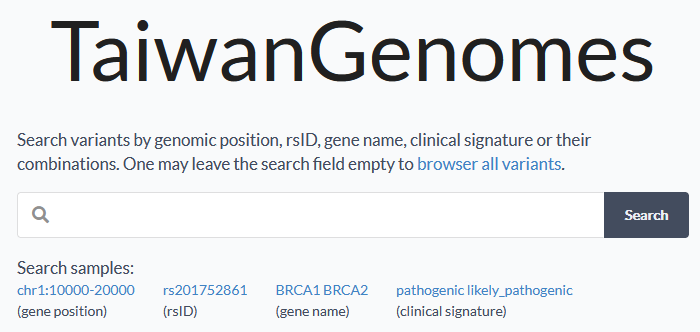
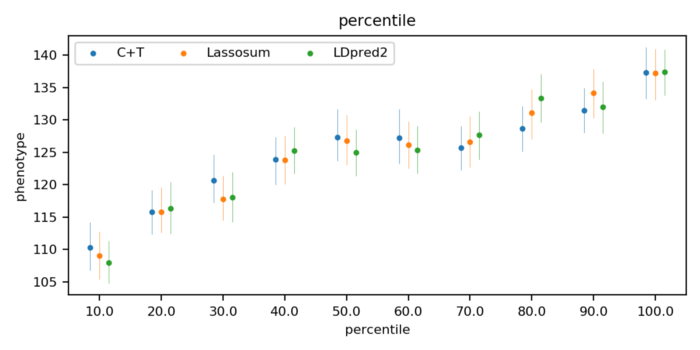
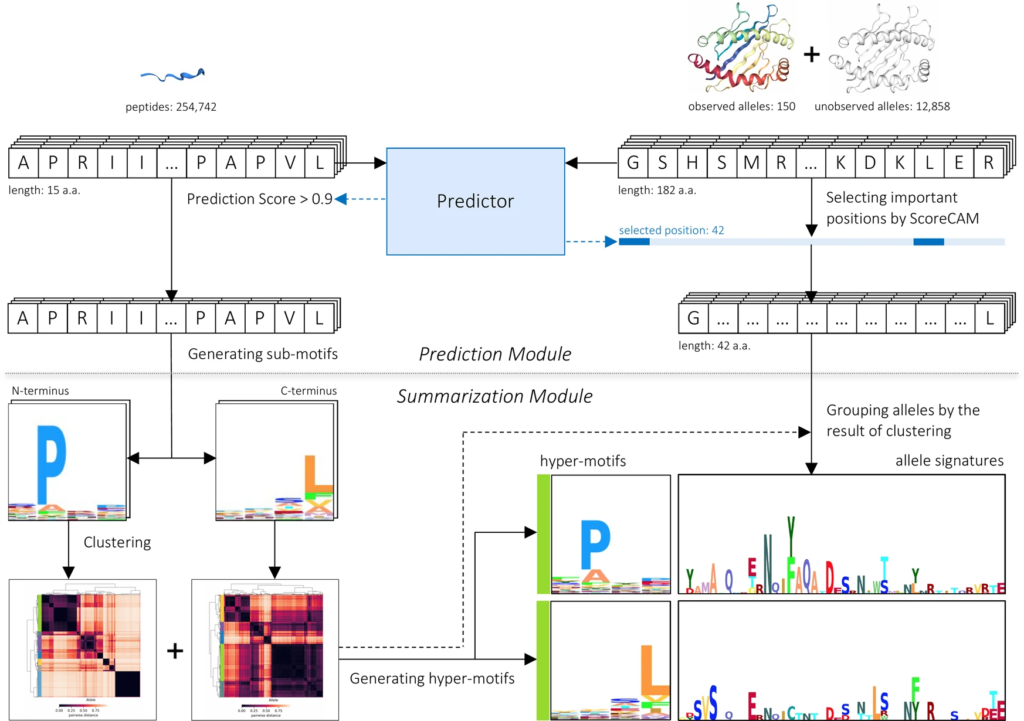
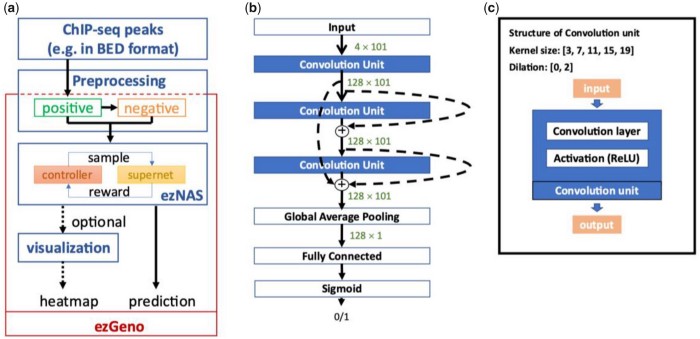
我的科技英文寫作,啟蒙於念碩士前的暑假 (1996),當時 Stanford 給我 admission 的條件是:要提前到學校參加暑期語言課程,其中包含一門科技英文寫作。當時 Stanford 圖書館的查詢系統還是終端機模式 (那是一個還沒有 Google Scholar 的時代),也就是純文字的界面,資料庫中也只能看到摘要,要取得全文還要進圖書館,找到期刊印出紙本。儘管如此,這門科技英文寫作還是幫助我養成許多做研究時該具備的重要能力,包含如何查找相關文獻,如何描述研究問題的背景,如何摘要前人的相關研究成果,如何清楚說出研究目標,如何具體描述自己的研究方法等等。